Convex optimization problems form the bulk of optimization problems formulated in Robotics. Even though a bulk of the interesting optimization problems are indeed non-convex, it turns out that most of them can be approximated as convex problems given certain ‘relaxations’. This is convenient because there exist a plethora of capable and fast convex optimization solvers that can be easily applied to solve for global solutions to these convex relaxations. The results from these solvers often tend to be good enough to be used as solutions to the original non-convex problem.
Before providing a formal definition for convex optimization problems, we will first formally define convex sets and convex functions.
A set  is convex if, for an
is convex if, for an  and
and ![\theta \in [0,1]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-2d99592a906d52159abbe93c543b39ab_l3.png "Rendered by QuickLaTeX.com") ,
,
![\[\theta x + (1 - \theta)y \in C\]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-ed1f69d8db70b4702b07e472b7969ff3_l3.png "Rendered by QuickLaTeX.com")
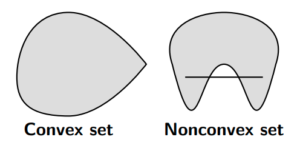
Intuitively, this means that if we take any two arbitrary elements in set and draw a line between them, all points on that line should also be elements in . The figure below shows an example of one convex and one non-convex set.
A function  is convex if its domain,
is convex if its domain,  is a convex set and if, for all
is a convex set and if, for all  and
and  ,
,  ,
,
![\[ f(\theta x + (1 - \theta)y) \leq \theta f(x) + (1 - \theta)f(y) \]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-89c3de81a309c21b9e0360d93f911aa4_l3.png "Rendered by QuickLaTeX.com")
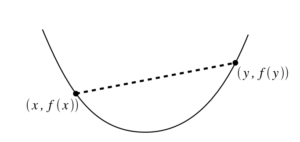
Intuitively, this means that, if we pick any two points on the graph of a convex function and draw a straight line to connect them, the portion of the function between these two points will lie below this straight line, as pictured below.
A function is strictly convex if the definition for function convexity above holds with strict inequality for  and
and  . A function
. A function  is concave if
is concave if  is convex and strictly concave if is strictly convex.
is convex and strictly concave if is strictly convex.
Some examples of univariate convex functions are Exponentials ( ), Negative logarithms (
), Negative logarithms ( ), Affine functions (
), Affine functions ( ), Quadratic functions (
), Quadratic functions ( ) where
) where  is symmetric matrix, etc.
is symmetric matrix, etc.
Formally a convex optimization problem is an optimization problem of the form
minimize 
subject to 
where is a convex function, is a convex set and  is the decision variable. A more specific formulation is
is the decision variable. A more specific formulation is
minimize
subject to 

To solve convex optimization problems, let’s first look at the unconstrained, one dimensional problem below
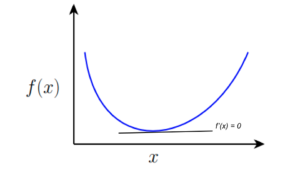
To find the minimum point  , we know from basic calculus that this point is where the first derivative of the function,
, we know from basic calculus that this point is where the first derivative of the function,  . As expected, this condition is satisfied at the minimum point of
. As expected, this condition is satisfied at the minimum point of
Generalizing for a multivariate function , the gradient of must be zero
![\[ \nabla _x f(x) = 0\]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-9ba42083bdab15a8f87ab159498cb835_l3.png "Rendered by QuickLaTeX.com")
For simple enough convex objective functions where it is possible, simply compute  , set it to
, set it to  and solve for the optimal decision variable.
and solve for the optimal decision variable.
For more complex functions where it is not easy or possible to come up with an analytic expression for the first derivative of the entire function, one could use either Gradient descent or Newton’s method to find the optimal decision variable.
Gradient descent proceeds iteratively by solving the gradient at a local region of the function and updating the value of the decision variable with a small multiple of the gradient. Thus, Repeat:
![\[x \leftarrow x - \alpha \nabla _x f(x)\]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-c9ad27f656ebf5f90a68174098c42e28_l3.png "Rendered by QuickLaTeX.com")
where  is a step size.
is a step size.
Newton’s method casts the problem as a root-finding problem to find a solution to the potentially nonlinear equation  . Each iteration of Newton’s method subtracts from the current guess, the product of the inverse of the local hessian of with the local gradient of , evaluated at the current guess. i.e.
. Each iteration of Newton’s method subtracts from the current guess, the product of the inverse of the local hessian of with the local gradient of , evaluated at the current guess. i.e.
![\[ x \leftarrow x - (\nabla ^2_x f(x))^{-1} \nabla _x f(x) \]](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-e23ca9fd0a540c63f9a754e2fbb5fcea_l3.png "Rendered by QuickLaTeX.com")
Even though an iteration of Newton’s method is more expensive than an iteration of Gradient descent because of the inversion of the hessian, Newton’s method converges to the optimal decision variable in much fewer iterations than Gradient descent.
Now to the more interesting Constrained Convex Optimization problems…
There are a number of methods for solving Constrained Convex Optimization problems. I will describe a few of them below, as well as their trade-offs.
Active-Set method is used when the user has some way of knowing which constraints are active or inactive at each point in time. Active constraints are the equality constraints whilst inactive constraints are the inequality constraints. Knowing which constraints are active enables the user to solve the optimization problem by setting up a Lagrangian and solving the resulting equation using the Gauss Newton method. The active set method can be very fast if the user knows the active set before hand. Else, it can get nasty.
Barrier/Interior point method integrates the inequality constraints into the objective function by subtracting the logarithm of the constraint function from the objective function. This logarithm ensures that decision variable values that violate the constraint blow up the objective function value and as a result, encourages optimization to avoid such values.
minimize
subject to 
becomes
minimize 
The Barrier method is the Gold standard for small-medium convex problems. It however requires a lot of hacks/tricks for non-convex problems.
Like the Barrier method, the Penalty method replaces inequality constraints with an objective term that penalizes violations
minimize
subject to
becomes
minimize ![f(x) + \frac{\rho}{2} [min(0, c(x))]^2](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-b09736e6e804069c9ed036588fbafc48_l3.png "Rendered by QuickLaTeX.com")
Even though the Penalty method is easy to implement, it has issues with ill-conditioning and is difficult to achieve high accuracy.
The Augmented Lagrangian is an extension of the Penalty method that incorporates both equality and inequality constraints to the objective function, i.e.
minimize ![f(x) - \lambda ^T c(x) + \frac{\rho}{2} [min (0, c(x))]^2](https://alphonsusadubredu.com/wp-content/ql-cache/quicklatex.com-320c261386c4bce78a39378f5bbc1348_l3.png "Rendered by QuickLaTeX.com")
Update  by offloading penalty term
by offloading penalty term  at each iteration.
at each iteration.
The Augmented Lagrangian fixes the ill-conditioning of the Penalty method and converges fast to moderate precision. It also works well on non-convex problems.
These Constrained Optimization algorithms are often very tricky to implement. Most practical applications of these algorithms use either commercially available or open-source careful implementations of these algorithms. Being recent convert into the Julia cult, I’d highly recommend JuMP to anyone looking to do optimization. JuMP provides a great, intuitive and general interface to use all the various commercial and non-commercial optimization solvers out there. This link lists all the solvers that JuMP supports. This link will also lead you to tutorials on the JuMP website that provide really useful examples to get you familiar with the JuMP usage.
This ends my essay on Convex Optimization. My next post will potentially dwell on Mixed Integer Programming only because it has caught my fancy these past few weeks.
Oyasumi nasai.