Here, I post questions whose answers are not entirely obvious to me. The hope is that, in the future, after I have garnered diverse troves of knowledge and experiences, the answers to these questions would reveal themselves to me. And I will be glad. Glad that in spite of the questionable endeavors my previous self has engaged in, I have been, at least, enlightened in the process… even if by just 1 candela (terrible joke, I know).
33. What’s a good way to cache MPC solves? MPC iterations can be computationally expensive and slow because the system is solving a whole new optimization problem in each iteration. What if we could cache an aspect of previous iterations so that the subsequent iterations are significantly faster? Warmstarting the decision variables with the previous iteration is one way to speed up subsequent iterations but it feels like we could reuse a lot more of the data from previous iterations considering the state doesn’t usually change drastically from one MPC tick to the next. Which data exactly can we reuse? How do we engineer this solution data recycling into a routine that is inexpensive to call?
32. Planning through contact is hard because contact events are often discrete and non-differentiable. The Mordatch-Todorov route (convex approximation of contact to allow for computing smooth gradients) has shown remarkable results in cartoon physics simulation. Can we realise equally remarkable results on physical robots using a similar approach?
31. Why is Hell regarded as a “bottomless pit” in the Bible?
A: It is often the case that no matter how terrible things are, there is always some bloody stupid thing you could do to make it worse.
30. “No tree, it is said, can grow to heaven unless its roots reach down to hell”. What did Carl Jung mean by this? How do we, as roots, guard ourselves from succumbing to the pleasures of hell? The pleasures of not having to take responsibility in spite of our suffering? How do we guard ourselves against the pleasures of victimhood?
A: A wise man once said, the antidote to chaos is the voluntary acceptance of responsibility; bearing your cross gallantly, so to speak. Living with the aim of justifying the privilege of your existence will keep you from succumbing to the pleasures of victimhood. Maybe…
29. Can robot task planning and search problems be formulated as Mixed Integer Programs and solved using MILP solvers? This could potentially provide avenues for incorporating the unique dynamic and kinematic constraints robots have in the real world, into the discrete planning problem.
A: I do exactly that in this project. Paper is in submission at IROS 2022 🙂
28. When I stare at the face of a person, I can often easily tell whether or not they are staring straight at my pupil. Why did humans evolve to be very good at detecting eye contact?
A: It’s been said that the eyes are a window to the soul. According to “experts”, the pupils of untalented liars generally shift when they lie. It might be that humans evolved the ability to detect eye contact as a mechanism for lie detection.
27. What is the evolutionary significance of emotions? Why did humans evolve to feel emotions? What role do emotions play in the survival of the human species?
26. When we watch an engaging movie, our physical environment dissolves away and our consciousness, for lack of a better word, is transported into the world the movie describes and we are able to engage with the artifacts in the movie’s world to the point where it seems almost real. How does our brain manage to do this? Why did our brain evolve the ability to simulate virtual worlds?
25. Why do people scream when they are terrified?
24. Can low-cost robots with cheap sensors and actuators be made as useful as their expensive counterparts through algorithmic advances in probabilistic reasoning? What new ideas need to be generated or old ideas be dug up to make this possible?
23. Clowns are figures of instant amusement and joy. If so, why is it that clowns are often employed as psychotic monsters in western horror literature? Think of characters like Pennywise, The Joker, Poltergeist, Wrinkles, etc. Why is this contradiction so prevalent in our stories? Could this be a portrayal of the archetypal lesson that instant gratification leads to future tragedies? Or that, people who often portray themselves as harmless and innocuous are in fact monsters in disguise?
22. What makes an event memorable? Why do humans remember certain things and forget others? Why do humans have memory? What is the evolutionary importance of memory?
21. Are we good or are we just afraid of the consequences of being bad? If we were put in a situation where we could commit vile acts without any negative consequences, would we still be good?
20. What would be the largest, most effective, most pleasing of all possible sacrifices? How good might the best possible future be if the most effective sacrifice is made?
19. Why does Belief Propagation work?
18. Are our pets spying on us? Are our pets deceiving us? Animals have often displayed uncanny levels of intelligence that is usually dismissed as a fluke. Could it be that some band of animals are indeed just as smart as humans and have been concealing their intelligence in fear of being exploited by humans? Could they be plotting against us while biding their time? What collective measures should we put in place to defend ourselves in the event of an animal uprising?
17. Why does music inspire emotions in people? Is there an evolutionary explanation to this? What is it about the rhythm in music and structured poetry that either delights or distresses people? Could it be that our primal consciousness recognizes beauty in the structure and rhythm of music? How does our primal consciousness even define beauty? Or are our basal emotions represented in our brain in a similar form as music, such that whenever we hear music that has a close enough rhythm and tune to these representations, the corresponding emotions are somehow triggered through resonance? Could we design similar representations in robots, where certain robot actions are triggered when they hear certain rhythms? This could be an interesting technique for inter-robot communication in situations where tele-communication between robots is limited or unavailable. It could also be an interesting way for humans to communicate with robots, by breaking the language barrier. Just sing the right tune to the robot and get it to clean your bathroom for you. How do we go about building such a system?
16. Long horizon planning in the robotics literature is usually performed by coupling high-level symbolic planning with low-level motion planning. Low-level motion planning is performed in the continuous space where the robot tries to find optimal collision-free trajectories along which to move to change its geometric state. These trajectories are planned on a static model of the robot’s environment and assume that the environment would remain the same as the robot executes these trajectories. But in practice, it often happens that in the course of the execution of a trajectory, the robot unintentionally changes the environment by knocking off a plate or shifting a book, making the remainder of the planned trajectory no longer collision-free or optimal. Is modern motion planning formulated in the right manner? Should reactive feedback controllers replace motion planning in long-horizon planning tasks? How would such a problem be formulated? What would the feedback signal be in such controllers? How do we ensure that the controllers run at a fast enough frequency to react to real-time changes in the robot’s environment? A possible setup for long horizon planning could be [Symbolic Planner -> Reactive controller+Inverse Kinematics]. Would it be possible to do avoid Motion Planning entirely?
15. The Task and Motion Planning community have done some phenomenal work in integrating the symbolic and discrete task planning with the more continuous motion planning. However, the symbolic domain description, operators, fluents and pre-conditions needed for task planning are usually specified by hand. Are there ways to exploit the recent developments in Neuro-symbolic AI by employing such techniques to learn to develop symbolic representations when given a problem description?
14. Why is meta-learning important or even necessary? Does meta-learning a task produce much better results in terms of sample efficiency and speed of convergence than regular reinforcement learning algorithms?
A: Also known as “Learning to learn”, meta-learning is a way of training agents (neural nets) to effectively learn multiple tasks. This way, with just a few examples, the agent can quickly learn to perform different tasks. The hope is that, by training them to solve multiple tasks, the agents will be able to tap into previous experiences to reduce the number of samples or gradient updates needed to learn a new task. Chelsea Finn showed in her work on Model-Agnostic Meta Learning (MAML) that, coupling MAML with Policy Gradients allows a simulated robot to adapt its locomotion and speed in a single gradient update. Meta-Learning has also been used to enhance Few-shot image classification and neural network optimization.
13. Chelsea Finn and Sergey Levine have done some work in getting robots to learn skills from raw videos. It basically involved predicting the next frame in a sequence of image frames. Is this approach viable? Is this the right direction to head towards?
A: See the answer to question 12 below.
12. How can Yoshua Bengio’s recent works on learning disentangled representations be adapted to enable robots to learn skills from videos or a sequence of image frames?
A: The aim of video prediction in robot learning is to enable the robot to learn to predict the next frame of a video. Its proponents hope that by this, the robot would learn the dynamics of objects in their environment; essentially the affordances of objects. Work on Unsupervised learning of video prediction for physical Interaction by Chelsea FInn, Ian Goodfellow and Sergey Levine focus on this problem by developing a model that explicitly models the pixel motion by predicting a distribution of pixels over pixel motion from the previous frame. Work by Emily Denton and Vighnesh Birodkar on Unsupervised Learning of Disentangled representations from video proposes a new adversarial loss to factorize video frames into the static part and the temporally varying part. This disentangled representation can then be used to learn video prediction.
Even though video prediction might be a valid way for an agent to learn about the physical dynamics of the real world, I still think that, for purely practical robotics purposes, they’re focusing on the wrong problem and use case. The better problem, I believe, would be to figure out how to get robots to learn skills from videos of human demonstrations. With this ability, the robot could, just like humans, learn different skills like cooking, cleaning, carpentry and other manual tasks straight from YouTube videos, first from just observing the humans bodily actions. And maybe as the robot develops further, it can be made to understand the full extent of the video by both considering the bodily actions and understanding the words uttered by the human. And I don’t see a direct application where mere video prediction addresses these use cases.
11. According to George Konidaris, “The right symbolic state representation depends on the skills available to the agent”. This seems reasonable considering there could be unreachable states if the opposite is done. Learning skills through skill discovery is however a very hard problem. What are some ways of reducing the difficulty of skill discovery? Or is there a much more feasible alternative to pursue?
A: Learning skills through skill discovery is a hard problem primarily because it relies on an RL algorithm to learn a skill that solves the entire problem and then segments this skill into sub-skills. Most SOTA RL algorithms are notorious for being sample inefficient and brittle. A much more realistic way to learn skills would be through an imitation learning and reinforcement learning cocktail, where the agent learns the skill from an expert demonstration and then uses reinforcement learning to refine this learned skill. This process is both faster and sample efficient and has been employed in numerous works like Hierarchical Imitation and Reinforcement Learning by Hoang Le et. al from Caltech and Relay Policy Learning by Animesh Gupta et. al from UC Berkeley. There’s still a lot more work to be done to make these approaches real-time. As this would be required by a robot deployed in the real world.
10. What are the most important problems in domestic robotics research?
A: Here’s a list of what I think are the most important problems in domestic robotics research. This list is in no way objective and is mostly biased by my interests.
- Performing long-horizon tasks in large state spaces
- Robots today are mainly able to perform short horizon tasks like pick-and-place tasks that require little temporal reasoning. In order to get robots to effectively assist people in the homes, hospitals and social environments, robots should be able to reason and plan for long horizons to perform complex tasks like cleaning up a house, cooking a meal, administering medication to the sick, going on errands, etc.
- Cost effective mobile manipulator robots
- The most prominent mobile manipulator robots used in robotics research today cost tens of thousands of dollars. The fetch mobile manipulator robot costs between $70,000 to $100,000. This cost is much more expensive than most labs can afford today. Even though there are cheaper alternatives like the Pyrobot from CMU which costs $5,000, the scale of this robot is not large enough to perform any useful domestic tasks. More work into developing useful, cost effective mobile manipulator robots is needed if robots are going to be a common sight in homes.
- Cost effective, deformable end-effectors for manipulating objects of arbitrary geometry and size.
9. Why is there this inexplicable craze for end-to-end robot learning on the West coast and a clamoring for model-based methods on the East coast? Who is right? Is there a middle ground? Is the middle-ground reasonable?
A: Model-based robotics relies on hand-crafted controllers and dynamics models developed from all the work in mechanics dating back to Newton’s F=ma. The pipeline for solving a robotics problem has always been to first develop a mathematical model (plant) of the domain, connect a hand-crafted controller to it to feed it optimized control inputs, connect a sensor to the output of the plant to sense the effect of the plant dynamics on the world, measure the error between the desired effect and the actual effect and feed this error into the controller to inform it in its effort to feed optimal control inputs to the plant. This pipeline, called the closed-loop feedback control, is the core of classical, model-based robotics.
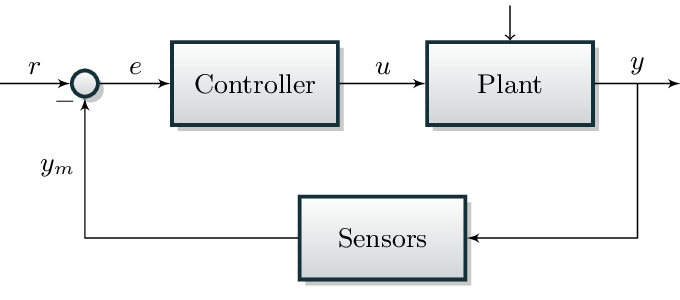
The major drawbacks with this approach are two-fold. First, if there are slight errors from one module of this pipeline, say the sensors, the errors would be propagated to the controller which in turn would produce control inputs with compounded errors to the plant and causes the plant to act in undesired ways leading to the ultimate failure of the system. The second drawback is that, it is really difficult to design effective controllers or develop accurate enough models for complex systems with high degrees of freedom. These, in part, account for why robots aren’t actively deployed in our homes, hospitals and on our streets as these domains are unstructured, highly uncertain, dark and full of terrors.
The philosophy of End-to-end robot learning is on the other extreme of the spectrum. Proponents of this philosophy believe that given enough data and through interaction with the real-world, a robot can learn on its own all the policy it needs to perform tasks successfully in the world. A policy maps states to actions; it decides which actions the robot takes at each state it finds itself in. Given the optimal policy, the robot would be able to perform tasks successfully in the world, without any explicit model. They propose to learn this policy through reinforcement learning, where the agent optimizes for taking actions in the world which result in positive rewards. Essentially avoiding the use of any form of hand-crafted models or controllers.
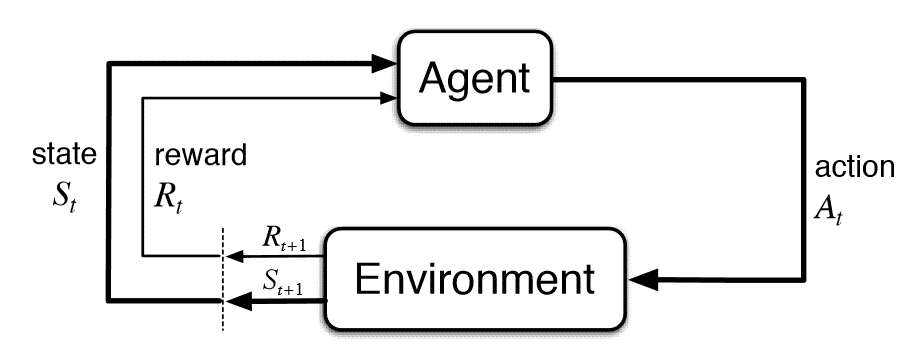
This approach, although sexy and cool, has numerous significant drawbacks. First, the order of magnitude of trials needed for agents to learn policies that efficiently perform a task are in the millions and sometimes billions. As such, agents are generally trained only in simulation as these could easily be sped up with no physical repercussions. As far as I know, to date, no agents are trained end-to-end on real robots. Could we then just train agents in simulation and transfer the policies to real-world systems? Not quite. This approach, commonly referred to as Sim2Real on its own doesn’t quite work out because the real world is far more complex than any simulator can express and as such policies trained in simulation don’t generalize to real world environments or even to other simulated environments. Approaches like Domain Randomization seek to inculcate random noise in the simulated domain during the training of the policy in the hope that, the trained policy becomes robust to the kinds of noise and uncertainty in the real world. This has made Sim2Real transfer of policies possible in short-horizon, ‘clean’ tasks like manipulating objects on a flat, open surface. It is however not evident that this would work in much more complex tasks with extended horizons and large state spaces.
There have been some recent approaches to merge the benefits of both end-to-end robot learning and model-based robotics. Prominent amongst these is work by Sax et. al where they inculcate priors like the 3D structure of the world, distance, etc. (which are common with model based approaches) into training RL agents. Agents trained with this approach were more sample efficient and generalized better in new environments than those without these priors.
Like the classical model-based roboticists, I believe that it is infeasible to require robots to learn end-to-end policies from scratch without any form of priors about the real world. I also believe that the ideal domestic robot should already come with a built-in model of the world which it can update quickly on the fly as it encounters more data or is taught to perform a task by its human owner. I talk more about my fuzzy path to the realization of the dream of domestic robots in this blog post.
8. Would it be necessary to disentangle latent vectors before learning robot skills? If so, what are the state-of-the-art approaches in learning disentanglement of the latent space? Would learning robot skills from latent space instead of pixel space enhance generalization?
A: The amazing, well defined, well experimented work by Sasha Sax and collaborators focuses on exactly this question. They try to find out whether performing some form of disentanglement on the pixel information before learning policies from them has any effect on the performance of the policy they train. They call the disentangled representations “mid-level perception”. They disentangle features like edges, object classes, distances, 3D keypoints. Through their rigorous experimentation on Gibson database, which consists of 3D scans and reconstructions of real-world environment, they found that first disentangling the mid-level priors before training a policy using RL results in significant performance improvements over end-to-end RL approaches in navigation, local planning and exploration. The policies they trained were also significantly more generalizable across different indoor environments.
They however also found out that the right set of features to entangle depends on the specific task at hand. Object-class disentanglement was the best prior for the navigation task. Distance disentanglement was the best prior for the exploration task. 3D keypoints disentanglement was best for local planning.
7. Can we expect current model-free reinforcement learning approaches to generalize to longer horizon tasks on real-life robots? It seems like all they can do at this point is to learn how to stack blocks. Or should more attention be diverted towards model-based approaches even though they are overly sample-inefficient?
A: Vanilla reinforcement learning algorithms are unable to effectively learn to solve long horizon tasks because such tasks have sparse rewards and as such, are difficult to assign credit duly to which actions generate rewards and which ones don’t. There have been numerous efforts to get reinforcement learning to learn to perform long-horizon tasks; many of which involve a blend of both reinforcement learning and imitation learning. Imitation learning involves training a policy to perform a task through learning from expert demonstrations. DAgger, the most prominent imitation learning algorithm requires that an expert step in to correct the policy whenever it takes the wrong action after which it augments this knowledge into its bank, updates its policy and repeats the cycle until it converges to an acceptable performance. Even though imitation learning could efficiently enable an agent to learn tasks of significantly long horizons, the need for constant expert demonstrations doesn’t make it ideal for some use cases. Also, the learned policy is upper-bounded by the expert’s proficiency. It can’t get any better than the expert demonstration.
Merging the good sides of both RL and IL have demonstrated some promising results so far. In the paper on Hierarchical Imitation and Reinforcement Learning by Hoang Le et. al, the authors employ a hierarchical framework to reduce the number of times the expert has to intervene during learning. They do this by learning hierarchical policies based on ‘macro-actions’. Macro-actions are temporally extended actions an agent can take. The authors develop a meta-controller that maps states to macro-actions. Each macro-action consists of sub-policies the map the state to low-level actions. Sub-policies can also trigger a ‘stop’ signal which transitions control back to the meta-controller.
In the course of training,
- Label only the macro-action as correct if the meta-controller chooses the right macro-action and the corresponding sub-policies execute successfully.
- Label only the macro-action as wrong if the meta-controller chooses the wrong macro-action.
- If the meta-controller chooses the right macro-action and the corresponding sub-policies fail to execute, label the macro-action as correct and go down to each action in the sub-policy and correct all its low-level actions.
By doing this, they are able to significantly reduce the number of times the expert has to interfere as well as the rate of convergence. This hierarchical approach enables the model to converge to perfect performance significantly faster than any flat imitation learning algorithm in game domains.
If the sub-policies solve short-horizon tasks, reinforcement learning could instead be used to learn good sub-policies while everything else remains the same.
6. How does the skill-chaining algorithm discover promising sub-goals?
A: Skill chaining is a method developed by George Konidaris to enable an agent to learn action abstractions (skills) to complete a task. It employs a popular method called pre-image backchaining where the skill chain is developed backwards from the goal, all the way to the initial state. By doing this, he avoids the damnable event of falling into an infinite branching factor when doing the normal thing of starting the search from the initial state. To answer the question above directly, the agent doesn’t have to worry about discovering promising sub-goals since the search is started from the target state and then goes backwards to the start state. All the agent does is to first develop a skill to reach the final target, then develop a skill to reach the initiation state of the previous skill and repeat this cycle til it reaches its desired start state. Here is a blog post I wrote about George Konidaris’s Skill chaining algorithm.
5. How do you perform long horizon planning with the aid of Hierarchical Reinforcement Learning?
A: Humans naturally reason over tasks through hierarchies of abstractions. To perform a long-horizon task like travelling to Ghana from Boston, I reason over and string together high-level actions like “packing my luggage”, “taking a taxi to the airport”, “going through TSA checkpoints”, “board the plane” and “alighting when the plane arrives at the airport in Ghana”. Each of these high-level actions, are abstractions that represent a set of low-level actions stringed together in a specific manner to achieve an end goal. For instance, the abstraction, “packing my luggage” is composed of sub-actions like “picking up the clothes”, “folding them”, “arranging them orderly in the suitcase”, etc. It is not hard to image these sub-actions further broken down info finer and finer actions, all the way down to the level of stretching and contraction of muscles, forming a hierarchy of multiple levels of abstraction, each with increasing number of sub-actions. As such, the need to reason over hierarchies of abstraction is obvious. Reasoning over abstractions enables quicker and longer horizon planning as there are generally fewer abstract states and actions to consider.
Likewise, hierarchical reasoning is essential for planning of long horizon tasks by robots. By generating a hierarchy of actions, the robot can string together high-level actions in the right sequence to perform long-horizon tasks. The major question now becomes; how do we get the robot to build these abstraction hierarchies? Should we manually design them and program them into the robot or should the robot learn the hierarchies on its own? The former approach, through quick, robust and reliable would require us to program-in new hierarchies for every task if the hierarchies aren’t sufficiently generalizable across different tasks. The latter approach would be to enable the robot to learn action hierarchies for each task or family of related tasks. The most prominent way to learn such hierarchies today is through Hierarchical Reinforcement Learning (HRL). HRL has seen some success in both the games domain and in simulation domains. It is however hard for this success to translate to real-world robots since HRL algorithms are sample inefficient and are impractical to train from scratch on a physical robot. I write about a great way of learning action abstractions(skills) for HRL through skill chaining in this blog post.
4. What is Model Predictive Control all about?
A: Model Predictive Control is a feedback control algorithm that uses a model to make predictions about future outputs of the model. I wrote a blog post on this topic here.
3. What is Optimal Control all about?
2. Is a Bug algorithm used in Roomba?
A: Not specifically. According to this article, roomba moves in an outward-moving spiral, heads to the perimeter of the room til it hits an obstacle and performs wall-following until the clean-up time is over.
1.What is KL Divergence and why do I keep seeing it in papers I read?
A: I answer this question in this blog post