My fascination about the idea of domestic assistant robots began when I first watched Meet the Robinsons on a Cathode Ray Tube television in my parents room 12 years ago. My favorite character was (obviously) Carl, the perpetually anxious robot who was essentially in-charge of almost everything at home; from cooking meals and cleaning up, to giving morale-boosting advice to Lewis as he prepared to take on the Bowler-hat guy (not a very intimidating name for a villain, IMO). A curious feature of Carl’s design was that, he seemed to have a specialized tool for almost every task embedded somewhere on his robotic torso. Even though he had the general form of a human anatomy, his body was, I daresay, designed in a manner that directly tackled all the tasks he was built to perform. His form followed his function. He was designed, not on the basis of human anatomy and skeletal control, but entirely based on how well his form can perform the functions he was built for.
It was in this spirit that we (myself, my PI and a grad student) designed and built Cartbot (accepted at the ICHMS 2020 conference!), a low-cost fully-teleoperated domestic assistant robot to perform certain kitchen tasks. The defining principle in building Cartbot was to build a robot, as low-cost as possible, and with just the right physical complexity and degrees-of-freedom to perform a select set of kitchen tasks. We validated our implementation by inviting a number of paraplegics into the lab, to tele-operate Cartbot to perform the set of kitchen tasks.
A video of tele-operated Cartbot doing some kitchen work:
(Getting back on track) I believe the overly human-focused design choices (as against task-focused ones) made in most robotics research endeavors are one of the numerous factors that hold back the progression of robots from the labs to the homes. If we viewed domestic assistant robots more as gadgets than as human-like replacements of the caretaker, the screen of complexity through which we view the domestic robot problem could be much clearer and our efforts would be much more tractable, goal-oriented and much more likely to be deployed soon in the real world. The validity of my claim is evident from the major feats of engineering that have been inspired by biological creatures. The invention of airplanes was inspired by flying birds even though current airplanes employ a significantly different flying mechanism from that of birds. Modern neural networks, although inspired by synapse connections in the mammalian brain, do not (as far as we know) learn exactly like the brain. Decoupling the task we are trying to solve with domestic robots from the way a typical human would solve it, could possibly simplify to some degree the nature of the domestic robot problem and guide us to find tractable solutions with strong performance guarantees in the real world.
In as much as it is necessary to avoid the pitfall of trying to develop domestic robots as like-for-like human replacements, there is still the need to develop structures through which humans can communicate intentions, directions or knowledge to robots in a natural manner. It is futile (or at least, hard) to attempt to program in the factory, all the necessary skills and knowledge the domestic robot needs to perform its functions, before the robot is deployed in the home. The robot would most certainly need to learn or update its priors in the new home. Learning might not be necessary for robots like a Roomba or any other vacuum cleaning robot whose only job when turned on is to move around the house in a pattern and suck out the grime from the floor. A robot tasked with performing a more complex task however would need to learn on the job since the prior model programmed into it from the factory might not be an accurate enough representation of its new home to be used to perform its tasks. Even if we ignored all uncertainty and made the strong assumption that most homes have the same layout of rooms, furniture, and utensil arrangement, it would be significantly difficult to develop algorithms that were general enough to successfully function in diverse houses and even more difficult to account for all the necessary tasks people would want their domestic robots to perform. Or maybe, for starters, you could just create a fixed set of tasks the robot can perform with a fixed set of skills, and nothing else. In this case the robot would not have to do any form of learning. All it would do would simply be to receive a command, use its perception system to create a representation of its environment, generate a task and motion plan using this representation for the given command and send the right torques and velocities to its actuators to get it to perform its task. No learning whatsoever involved. The robot is simply a gadget that does its job, and nothing else. No skills gained, no skills lost, chicken’s great, all’s right with the world. This is essentially how most gadgets and consumer tech works (except for recent phones and computers that occasionally update themselves and learn from their user’s behaviors). Even though this is by no means a straightforward endeavor to pursue, the years of robotics research in perception, planning and control have laid out solid foundations upon which we can develop task-specific domestic robots. One could argue (and I agree) that we should first aim to develop domestic robots that are like this, with a static skill set and as our efforts in robot learning progresses, we gradually build in capabilities that enable them to learn new skills from their users; in a way emulating the progress story of smartphones.
How should the domestic robot learn these new skills from its user? How should the robot compose these learnt skills to perform long-horizon tasks? These are the two major questions robot learning research should try to answer. Most current efforts in robot learning research focus on answering the first question: how to learn. Earlier efforts tried to tackle this problem by learning from demonstration. In this setting, the robot is provided with expert demonstration through various media like kinesthetics (here, the expert demonstration is acquired by the human teacher physically moving the robot over a trajectory), tele-operation (the human gives expert demonstration to the robot by tele-operating the robot to perform the desired task), human tracking (the robot tracks the skeletal motion of the person and records this trajectory as expert demonstration) and more recently, through imagination; yes that’s right..imagination (here, the robot is provided with a video of a human performing a task. The robot then ‘imagines’ itself as the human and records its imaginary trajectories as expert demonstration. More about this approach here). Once this expert trajectory is acquired, the robot learns a distribution of this demonstration in a manner that enables it to execute the demonstrated task in arbitrary initial conditions. The caveat with learning from demonstration is that, the robot can only be as good as the expert demonstration and never better. Which, to be fair, is fine and perfectly sufficient for a domestic assistant robot provided the robot’s learned skill is close enough to the expert demonstration. We can’t all clean the kitchen floor or wash the dishes as well as mummy can, but we definitely survive, do we not? Besides, human students are rarely ever as good as their teachers. More recent efforts in robot learning employ reinforcement learning strategies to teach robots to perform tasks. In this formulation, the agent learns a policy to perform the task through the optimization of a specified reward function. A policy dictates what actions the agent performs at each state. An example of a reward function for learning a locomotion policy for a simulated humanoid could be the distance of the head of the humanoid from the ground. A demonstration of the performance of the learnt policy after a number of training cycles is shown in the video below.
The problem with the Reinforcement Learning (RL) formulation is that, most established RL algorithms are essentially trial-and-error approaches, albeit somewhat clever. The agent essentially tries out random actions in its action space at the initial stage and after each cycle, update its policy to choose with some probability, the random actions that resulted in positive rewards. And keeps repeating this cycle until it ends up with a policy that succeeds more often. And this takes hundreds of thousands of training cycles. Even though this might be a somewhat oversimplification of RL algorithms, at their core, after removing all the embellishments they are shrouded in, this is essentially their naked state. And there’s a lot to despise, or to put it more kindly: be skeptical of. The prime quandary with RL is that, we can’t obviously afford to run hundreds of thousands of training cycles on physical robots because, unlike fancy simulations, resetting the state of the robot before each training cycle (eg. training to walk upright like in the video above) might not be advisable or even possible on a physical humanoid robot as it would inevitably break at the 15th or 20th cycle. Even training for much simpler tasks like object manipulation with physical robot arms might still not be practical for similar reasons. Real-life robots tend to remain broken after they are damaged. They simply don’t re-spawn. Why don’t we just train the agents in simulation and transfer the learnt policies to the real robot? Turns out policies learnt in simulations don’t generalize well in the real world. Why? Because the simplistic representation of the world in the simulator is not rich enough to model the complexities of the physical forces, known and unknown, that come into play when robots operate in the real world. There have been a number of efforts into sim-to-real knowledge transfer but as far as I know, that hasn’t yielded much success. Prominent amongst the sim-to-real techniques is the Domain Randomization technique introduced by Josh Tobin and collaborators which achieved some level of success in direct policy transfer from simulation to a real robot. But the task focused on in this work was a simple manipulation task of colored blocks on a flat surface and I doubt this relative success would carry on to more complex tasks in more nuanced domains.
More recent work in RL, particularly this recent work from Sergey Levine’s lab in Berkeley and some much older work by Jens Kober and Jan Peters have attempted to combine learning from demonstrations and RL by using the expert demonstrations to guide the action exploration performed by the RL agent to a local region in the action space. This way, the policy would converge converge to the optimal at a much faster rate. Although they converge much faster with much better sample efficiency than pure RL algorithms, they are still not sample efficient enough to be realistically trained on physical robots.
Once the domestic robot acquires these skills, how does it compose them to perform a long horizon task? How should it internally represent its environment in order to plan which steps to take to accomplish this goal? What is the right abstraction to build? Should this abstraction mainly be driven by the states of the robot’s environment or the skills the robot has in its repertoire? State-driven abstraction methods develop a mapping from the original state space (i.e. the physical world) to a more compact state space/ representation with which reasoning is performed. Majority of robotics employs state abstraction to represent domains in which they function. Robot navigation generally uses prior maps, usually Occupancy Grid Maps to represent the existence or absence of obstacles in the environment they navigate in, so as to generate path plans with this map representation to avoid the obstacles and successfully navigate to their goal positions. Work by Chad Jenkins and collaborators on Semantic Robot programming propose a method for developing a graph representation of a domain by capturing the spatial relationships between objects that make up the domain. The robot builds this abstraction for both the initial state of the domain and the goal state that a human specifies on the fly and employs graph planning algorithms to plan actions to transform the initial representation to the goal representation. I wrote a blog post on this interesting work here.
More recent methods employ autoencoders to learn compact representations usually in the form of low-dimensional vectors, from data. Action-driven abstraction methods involve developing a set of high-level skills from low-level actions (usually called primitives). High-level skills (popularly referred to as options in literature) usually come with a set made up of initial conditions, a policy and a termination condition. Initial conditions represent the states from which the skill can be successfully executed. The policy determines which action to perform at each state. The termination condition decides when the execution of the skill is terminated. With the skill structural unit, long-horizon plans can be built and executed. Assume you, as a human, were an agent whose long-horizon task is to travel to Ghana. Your low-level primitives would be the movement of your body joints. Your high-level skill set could include a skill to book a flight, a skill to drive to the airport, go through customs, board the plane, etc. With these high level skills, you can construct a feasible plan to execute the long-horizon task of travelling to Ghana. For the ‘drive to the airport’ skill, the initial conditions would be: Have a car; have fuel in your car; know how to drive; sit in the driver’s seat. The policy would be the various driver controls you execute at each point on the road in order to get to the airport. The termination condition would be arriving at the airport. Assume you didn’t have these skill sets and only had low-level primitive actions. It would be significantly difficult (computationally intractable) to construct a valid plan to travel to Ghana if you reasoned on the level of torques and joint angles to set your joints to in order to get to Ghana. An agent’s set of skills can either be hard-coded into the agent or be learned and good arguments can be given for either methods. Hard-coding the agents skills would prevent the agent from performing undesired actions, like jump of the plane while on the way to Ghana. However, unless the skills are adequately general, new skills would have to be hard-coded into the agent for every new task. On the other hand, if the agent could autonomously learn the skills required for each task, we will have less work to do. The agent could however learn detrimental skills like jumping off the plane mid-flight, which will undoubtedly have undesired effects. Also, learning the initial conditions, policy and termination conditions of skills autonomously is not a trite problem and is generally performed using RL which has its own issues.
In his beautifully written journal paper, George Konidaris argues that the most effective way for agents to build abstract representations of their domain is to build state abstractions using high level skills the agent possesses. This way, the representation is independent of the complexity of the domain and every state in this domain is provably reachable by the agent. The figure below from his journal paper expresses this idea.
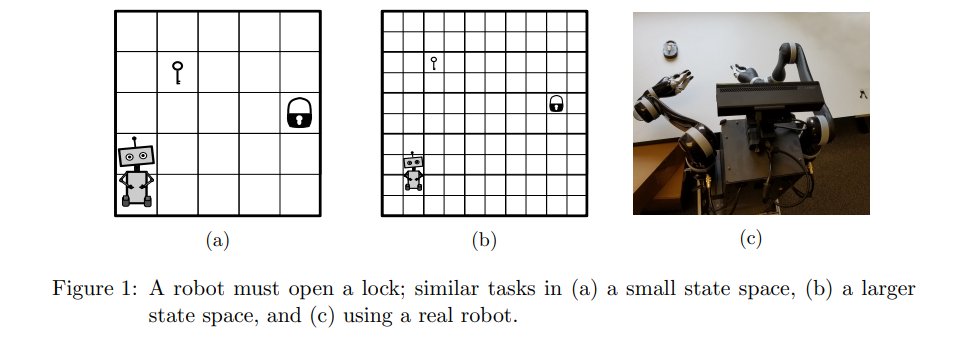
The figure above demonstrates similar problems in increasingly complex domains. The first domain is a grid world with few discrete states, the second is a grid world with much more discrete states and the third is the real world with continuous states. The agent’s task is to pick up the key and use it to open the lock. If given the necessary skills, each of these three problems is equivalent! An abstraction for these domains can simply be constructed from four boolean states; whether the agent is near the key, whether the agent is adjacent to the lock, whether the agent has the key and whether the lock is opened. The only difficulty would be in constructing the high-level skills for complex domains. But once the agent has these, size of the state space is irrelevant. The existence of these high-level skills in a way filters away the complexity of the domain such that only the essence of the problem remains. This is the power of building representations/abstractions using high-level skills. You can read more about this glorious 75-paged journal paper here.
The realization of the domestic robot dream has the potential to completely change the dynamics of domestic life as we know it. It will be most beneficial to the aged and the physically or mentally impaired who need constant domestic assistance. I am hopeful that, as the years ebb on, there will be significant continuous progress in realizing this dream. And I’ll be honored to contribute to this realization.
Im grateful for the blog. Much thanks again!
Informative article, just what I was looking for.
I really appreciate your help with my project!