While cheerily performing their chores at home, domestic-assistant robots will often come across a clutter of empty detergent containers, the toddler’s long lost feeding bottle, the TV remote you’ve been searching for for ages, amongst others. Poor Alfred the robot would have to figure out a way to de-clutter this unsightly hodge podge. This task might seem trite to a human of double-digit or even single-digit IQ, but to poor robot Alfred, it might as well be the Poincare’ conjecture.
Task and motion planning for robotic manipulation has seen significant progress over the years with the development of fast and tractable task and motion planners (Caelan R. Garrett et. al, 2018) that are capable of planning trajectories for complex mobile manipulation tasks in seconds if the problem is presented in the right representation. But real world problems are rarely ever presented in the right representation. Indeed, understanding and representing a real world scene in a way that is convenient for motion planners to reason about is the bulk of the difficulty in deploying robots into the real world.
There have been multiple efforts in developing scene understanding algorithms that transform the raw images captured by the robot’s vision system into meaningful representations the robot can use to plan motions and execute them to have a desired effect on its physical environment. Most of these approaches however assume that the robot’s environment is static or that the identities of all the objects are known or can be inferred by an idealized and perfect object recognition system. The problem with the static scene assumption is that, it assumes that the current states of the objects are independent from their previous states and as a result, the computational cost of inferring the states of objects grows exponentially with the number of objects in the scene. Object detection and recognition systems, which are of late dominated by Convolutional Neural Networks (CNN), though quite competent, are sometimes subject to various detection and recognition errors. As such, blindly assuming that they are perfect discriminators could lead to significant horrors that scale exponentially with the size and strength of the robot!
SUM (Sequential Scene Understanding and Manipulation), an algorithm developed and introduced by Zhiqiang Sui, Zheming Zhou, Zhen Zeng and Odest Chadwicke Jenkins addresses these two assumptions by considering the uncertainty in the object detection and recognition system in the estimation of the poses of objects in a cluttered scene maintained over time. The authors, Zhiqiang Sui, Zheming Zhou, Zhen Zeng and Odest Chadwicke Jenkins , are researchers in the Laboratory of Progress of the Michigan Robotics Institute. Here’s a video of the algorithm at work on a Fetch Robot.
And now, to my ‘low-dimensional representation’ of how this algorithm works .
SUM is an algorithm for determining the pose of objects in a clutter and manipulating them.
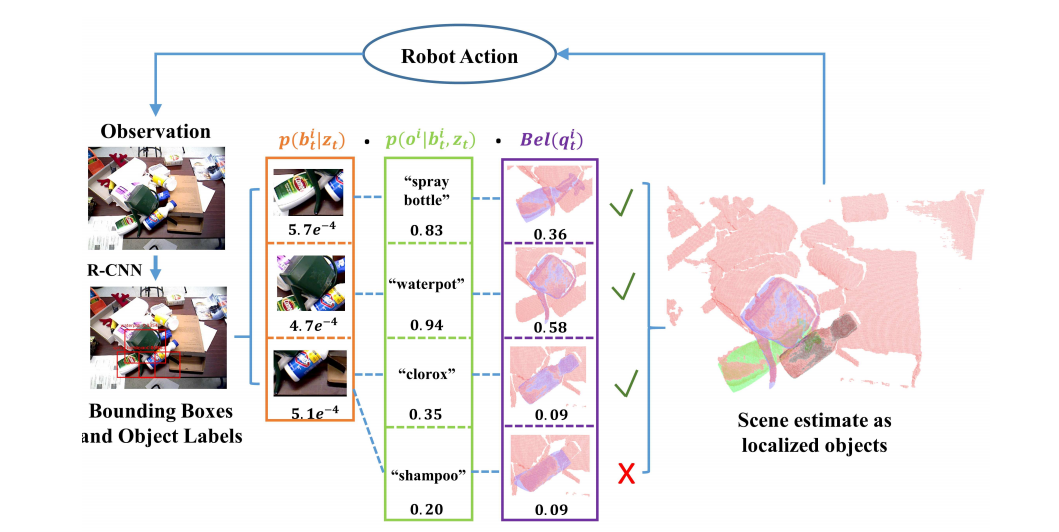
The state of each object at each time step is considered independent of the other objects and can be factored into 3 components, namely; object detection output (which involves generating a bounding box around the object, with a confidence estimate), object recognition output (which involves identifying the label of object) and a belief of the pose of the object. SUM is agnostic to specific kind of object detection and recognition discriminator that is employed (An R-CNN object detection and recognition model is employed in this work). All it requires is that, the discriminator outputs predictions with confidence estimates. Each detection comes with a bounding box with a probability of belonging to one of the objects of interest. Only object labels whose confidence estimate is greater than a threshold are accepted from the recognition discriminator and each accepted candidate object labels together with their bounding boxes are assigned a pose estimator which estimates the belief of the object’s pose. This assignment is performed by a greedy data association technique. Details about it can be found in the paper.
To estimate the pose belief of an object, a particle filter is employed to infer the true pose from the candidate object labels and bounding boxes. The candidates are weighted based on their confidence estimates from their object labels and bounding boxes. The weights are then re-sampled based on importance. Weighting is performed using a technique called iterated likelihood weighting.
Using the pose estimate with the greatest weight, a pick and place action is executed on the object. Gaussian components are then used to model how the object’s pose will change after the action is executed on it. If the action succeeds, the object assumes a new position which is the target position of the place action with some uncertainty. If it fails, the object stays at its previous position with some uncertainty. The pose belief of objects in the clutter is maintained over a sequence of actions. This enables SUM to perform robust scene estimation for objects whose pose do not remain static throughout the process.
This cycle of pose estimation and manipulation continues until there are no more objects in the clutter. Below is a figure from the original paper that depicts clearly the steps in the SUM algorithm.
The following are a few questions that arose as I read and thought about this paper.
I still don’t quite understand how maintaining a belief over scene state informed by past beliefs, a manipulation process model, and current object detections solves the problem of exponentially increasing complexity with increasing number of objects.
How does the robot decide the grasping orientation of its gripper for each object? Does it use a geometrical heuristic to predict which part of the object it should grasp and with which gripper orientation or is the grasping orientation learnt alongside the object detection for each of the objects?
Even for inference, the algorithm runs on a high end GPU (Nvidia Titan X Graphics card) which to my knowledge consumes a lot of energy and wouldn’t be practical on an actual mobile manipulator robot that is powered by a rechargeable battery. How can the algorithm be optimized to run on a regular processor or even a lower-end GPU like that of an Nvidia Jetson TX2 or a Jetson Xavier, assuming the object detection and recognition is the major computational bottleneck in the entire process.
Scene understanding, in my view, means creating useful representations of the environment as perceived by the robot and using these representations to plan and execute actions or make decisions. This paper tackles the problem of scene understanding by inferring the 6DOF pose information of objects in clutter (the useful representation) and using this information to manipulate the objects. Another representation employed by the authors of this work in a previous paper (which I pondered over) was a scene graph representation, where they inferred the semantic relationships between the objects through the robot’s 3D vision system to generate scene graphs which they used to plan actions to change the configuration of objects to a goal configuration. It seems to me that, the choice of representation of the robot’s environment depends on the task at hand and is coupled with its own specifically engineered method of inference and decision-making.
Should there be a more general form of representation that can be used for arbitrary tasks or should the kind of representation be task-specific? What form should this general representation take? Should this representation be learnt by, say a neural network, where it won’t be directly interpret-able or should it be cleverly hand-designed and easy to interpret?